RAID és ENBD - gyakorlati útmutató
Tomka Gergely
Contents
1. Barátunk, a merevlemez
2. Formula 1 az asztalon
3. Megb ízhatatlan Merevlemezek Hibatürö Tömbjei
3.1. Eszközeink
3.2. Elökészületek
3.3. RAID0
3.4. RAID1
3.5. Néhány fogalom
3.5.1. Szinkronizálás
3.5.2. Tartalék
3.5.3. Állapotok
3.6. RAID1 kalandok
3.7. RAID 1 0
3.8. RAID10
3.9. RAID5
4. Elmélet és gyakorlat
4.1. IDE vezérlök
4.2. IDE RAID vezérlök
4.3. SCSI RAID vezérlök
4.4. Hardveres vagy szoftveres RAID?
5. Logikus Ürméret Ügyvezetö
5.1. Fizikai kötet
5.2. Kötetcsoport
5.3. Logikai kötet
5.4. Növekedés
5.5. Variációk - mentés
6. Magunkon k ívül
6.1. A feladat
6.2. ENBD
6.3. Installálás
6.3.1. Elökészületek
6.3.2. Adó
6.3.3. Vevö
6.3.4. Diagnosztika, üzemzavarok
6.4. Élet az ENBD-vel
7. Összefoglalás
Bevezető
Joggal gondolhatják, hogy a frizbizésről fogok most előadást tartani, ismerve az előre megadott tárgyhoz való ragaszkodásomat. Kénytelen vagyok kiábrándítani a t-mobile körünkben megbúvó megfigyelőit, de nem. Az előadás leginkább merevlemezekről, az általuk elkövetett aljasságokról, és az ezek meghiúsítására kitervelt fondorlatokról fog szólni.
Sajnos gyakran fogok a gépjárműipar tapasztalataira hivatkozni. Nem véletlenül - a merevlemez az átlag számítógép leginkább ,,mozgó" alkatrésze, és gyártói, felhasználói sok hasznos gondolatot merítetnek a forgó alkatrészekkel több száz éve foglalkozó gépészmérnöki kultúrából.
Még sajnálatosabb, hogy a gyakorlati példák kivétel nélkül Linux szoftverraidra vonatkoznak. Ennek igen egyszerű oka van - nem használok mást. Hasonló megoldások léteznek más operációs rendszereken is. A Microsoft legfrisebb rendszerei is képesek RAID1-ről indulni, és a nagy fizetős unixok mindegyike ismer hasonló megoldásokat. A filozófia, a megfontolások, problémák azonosak, a megoldások részletei nem okvetlenül.
1 Barátunk, a merevlemez
Ma, mikor átkozzuk az alig fél éve vásárolt, ámde most már csak ablakon kihajításra alkalmas merevlemezünket, ritkán jut eszünkbe, honnan jutottunk el idáig. Apáink, ha egyáltalán megadatott nekik a mágneses adattárolás csodája, akkor is ma már nevetségesnek ható, órmótlan, energiaigényes és csenevész kapacitású eszközökkel dolgoztak. Szekvenciális elérésű szalagos egységek, misztikusan működő önbefűző egységekkel. Katódsugárcsöves memóriák, kemény sugárzásokkal. Mágnesdobok, több tíz kilós, nagy sebességgel forgó tárgyak. Még az első merevelemezek is inkább hasonlítottak mosógépekre, méretüket, súlyukat, kapacitásukat tekintve.
 Figure 1: Szalagos egység, 1953 - 15 Kb/s írás/olvasás
Figure 1: Szalagos egység, 1953 - 15 Kb/s írás/olvasás
 Figure 2: Merevlemez, 1953 - 5 mbyte, 15 korong, 61 cm átmérővel
Figure 2: Merevlemez, 1953 - 5 mbyte, 15 korong, 61 cm átmérővel
 Figure 3: Mágnesdob, 1956 - 4 kiloszó, 12500 RPM fordulatszám
Figure 3: Mágnesdob, 1956 - 4 kiloszó, 12500 RPM fordulatszám
 Figure 4: Az első PC-be szerelhető merevlemez, 1980 - 5 mbyte
Az első személyi számítógépbe szerelhető egységek koruk technológiai csodái voltak. Alig 10 kilós fémtárgyakba 5-10 millió byte adatot lehetett bezsúfolni - ehhez képest a holdutazás semmi. Ennek megfelelően áruk is vetekedett egy űrhajóéval. Kidolgozásuk súlyukhoz méltóan masszív volt. Nem csak hogy el lehetett tenni vele láb alól kellemetlen kollégánkat, de utána tovább működhetett mint adattároló egység. Ha valami váratlan nem történt egy ilyen szerkezettel, az működik ma is. Node kinek van ma szüksége 1 kg/mbyte teljesítményű féltéglákra?
Nekünk megbízható, tágas merevlemezekre van szükségünk. És ebből egyre kevesebb van. Joggal merül föl a kérdés, hogy ha ezt régen meg tudták oldani, most miért nem?
Figure 4: Az első PC-be szerelhető merevlemez, 1980 - 5 mbyte
Az első személyi számítógépbe szerelhető egységek koruk technológiai csodái voltak. Alig 10 kilós fémtárgyakba 5-10 millió byte adatot lehetett bezsúfolni - ehhez képest a holdutazás semmi. Ennek megfelelően áruk is vetekedett egy űrhajóéval. Kidolgozásuk súlyukhoz méltóan masszív volt. Nem csak hogy el lehetett tenni vele láb alól kellemetlen kollégánkat, de utána tovább működhetett mint adattároló egység. Ha valami váratlan nem történt egy ilyen szerkezettel, az működik ma is. Node kinek van ma szüksége 1 kg/mbyte teljesítményű féltéglákra?
Nekünk megbízható, tágas merevlemezekre van szükségünk. És ebből egyre kevesebb van. Joggal merül föl a kérdés, hogy ha ezt régen meg tudták oldani, most miért nem?
2 Formula 1 az asztalon
Kevesen gondolnak bele, de egy mai átlag asztali gépben van egy eszköz, ami olyan fordulatszámon működik, mint egy vagányabb sportkocsi. Kollégám autójának 1.6 literes benzinmotorján 6500 f/min-nél kezdődik a vörös vonal, ami fölött tartósan pörgetve a motor hamarosan megadja magát. Az átlagos merevlemez 7500-al pörög, ahol a VTI Hondák kivételével minden motor már leszabályozza magát. És kaphatóak 10000, sőt 15000 f/mint teljesítő lemezek, márpedig ez már az F1 autók jellemző számadata.
Márpedig egy F1 motor 600 kilométert, kb. 3 órát működik. Szerintem az olvasók mindegyike látott már ennél hosszabb élettartamú merevlemezt. Leszögezhetjük tehát, hogy ha mégis elpusztul egy modern merevlemez, akkor annak jó oka van erre.
A motorokkal összehasonlítás hoz egy másik hasznos tudnivalót. Pár éve a BMW büszkén jelentette be, hogy egy motorjuk (egy egész csinos soros hathengeres) százezer kilométernek megfelelő futási időt produkált számottevő kopás nélkül. A BMW rajongók elégedett morgással fogadták ezt a hírt, az úton-útfélen megtorpant bmwket kerülgető gépészek pedig gúnykacajjal. Ugyanis a benzinmotor, ha egyszer elindult, forog, és a terhelése nem változik hirtelen, akkor majdnem a végtelenségig elforog magában - az alkatrészek olajfilmen futnak, semmi sem kopik, minden alkatrész békésen zümmög. Az elindulás és megállás, ami meg tud ölni egy motort.
És ez természetesen igaz minden forgómozgást végző gépelemre, így kedvenc merevlemezünk korongjaira is. Nem meglepő tehát, hogy az évekig zokszó nélkül működő gép egy újraindításkor megmakacsolja magát, és soha többé nem indul el. Szerintem mindannyian találkoztunk már ilyen esettel - és szerintem gyakrabban, mint menet közben széthulló lemezzel.
Mindenképpen láthatjuk, hogy egy jól összerakott gépben a merevlemez a legnagyobb mozgó alkatrész, és rögtön a leggyorsabban mozgó is. Nem mellesleg a zajterhelésnek is jelentős részét okozzák, de a fenti versenygépekkel való összehasonlításból is látszik, inkább szabály, mint kivétel, hogy egy modern merevlemez tönkremegy.
3 Megbízhatatlan Merevlemezek Hibatűrő Tömbjei
A RAID technológiát, mint minden nyakatekert, és tisztán elméleti szempontból értelmetlen megoldást, a valós élet és a technika korlátjai hívták életre. Lassú a diszk? Osszuk el az írnivalót több diszk között! Nem bízunk a mozgó alkatrészekben? Írjuk ugyanazt egyszerre több helyre, hátha az egyik nem romlik el!
Azért mi sose felejtsük, hogy a raid nem a jó megoldás, hanem a kisebbik rossz. RAID tömböt használni mindig kompromisszum, még ha nem is mi tehetünk róla. És, természetesen, itt is érvényes a háromból kettő elve: olcsó, gyors, megbízható - bármelyik kettőt választhatjuk. Lássuk hát a főbb RAID szervezési elveket.
Az itt felsorolt 4 RAID szervezési elv feltételezi, hogy N darab, P kapacitású, nagyjából egyforma sebességű és méretű lemezzel dolgozunk. Vannak olyan szervezési elvek, melyek ezt nem feltételezik, például a RAID4 hasznos, ha az egyik diszkünk sokkal gyorsabb mint a többi. Ezekkel most nem foglalkozunk, mert a gyakorlatban nem túl sűrűn előforduló esetek.
3.1 Eszközeink
A szemléltetés legfőbb eszköze a Linux kernel szoftverraid megoldása lesz. A RAID teszteket 2.6.8.1-es kernellel végeztem, sajnos a szűkös hardverkészlet miatt sebességteszteket most nem tudtam csinálni.
- mdadm: a legfrisebb eszköz a szoftverraid piacon. A korábbi sok utilityt egy program helyettesíti, összehangolt, értelmes opciókkal. Megold mindent, létrehozást, karbantartást, figyelést, elemzést, ezek jó részét majd láthatjuk is.
- cat /proc/mdstat: a kernel ezen a fájlon át közli velünk, mi történik a raid eszközökkel. Informatív, és van benne egérmozi.
- bonnie++: általánosan használt blokkeszköz-teljesítménymérő program. Önmagában is hasznos adatokat szolgáltat, és ha futása közben megfigyeljük a gép általános hogylétét, például, hogy mennyi szabadideje marad a processzornak, egészen jól elképzelhetjük, hogy fog viselkedni a rendszer teher alatt.
- top, vmstat, stb.: változatos rendszerfigyelő és állapotvizsgáló programok, hogy teljes képet kapjunk a szemünk előtt történő eseményekről.
Ahelyett, hogy önnön grafomániámtól elbűvölt kockafejűként nekilátnék apróra elmagyarázni ezek működését, erőt veszek magamon, és menet közben, az egyes raid-szervezési elvek kipróbálásánál, gyakorlati példákon mutatom meg, mi merre hány paraméter. Szerintem ez nagyon hősies dolog tőlem.
3.2 Előkészületek
Hogy a szövegbe beszúrt példákat követhessük, el kell árulnom pár hasznos apróságot a Linux szoftverraidról. Hogyan hozhatjuk létre, hogyan ne hozzuk létre, mire ügyeljünk, stb.
Elsősorban szükségünk lesz blokkeszközökre. Szándékosan nem mondok diszket, vagy partíciót, mert a swraid zökkenőmentesen működik bármilyen blokkeszközre, legyen az loop, ndb, egész diszk, partíció, ramdiszk, scsi, ide, sata, mfm. Azért, ha lehet (általában lehet), hozzunk létre az adott blokkeszközön egy partíciót, mert úgy szebb.
Másodsorban, ha mód van rá, a partíciók típusát állítsuk be ,,Linux Raid Autodetect"-re, azaz FD-re. Ez egy hasznos szolgáltatása a linux swraidnak: nem holmi diszken/flopin tárolt konfigfájlból olvassa be a raid tömb adatait, hanem a raid tömb minden elemén eltárolja a tömb összes adatát. Így a kernel bootoláskor végigkérdezheti a diszkeket, hogy mi a helyzet, és még mielőtt megkezdené a rootpartíció használatát, elindíthatja a raid tömböket. Így lehet pogány varázslatok és initrd nélkül bootolni raid tömbről (igaz, csak RAID1-esről).
Ez a kis plusz más esetben is segít, például ha átrendeződnek a diszkek. Amikor egy szerverünkbe betettünk pár új scsi eszközt, akkor az addigi /dev/sda /dev/sdc lett, de a kernelt ez egyáltalán nem zavarta. Ami nekünk nagyon jól jött.
Sajnos, a felhasznált példák a létező legbutább megoldást használják - egy ide diszk négy partíciójával fogok bűvészkedni. Az élet kegyetlen. Később ismertetem, hogy ez miért butaság.
Ez az olcsó és gyors kategória. Két lemezt ,,összefűzünk", olyan furmányos módon, hogy minden fájl minden páros számú blokkját az egyik, páratlan számú blokkját a másik lemezre írjuk. Így, mint azt ujjainkon is kiszámolhatjuk, az írási és olvasási sebesség kétszeresére nő. RAID0 tömbökkel egészen hihetetlen sebességeket érhetünk el, már a háztartásban megtalálható eszközökkel is kitömhetjük a rendszerbuszt (például SATA diszkekkel).
Ha olcsó és gyors, akkor nem megbízható - így van ezzel a RAID0 is. Ha a játékban résztvevő bármelyik diszk meghal, akkor kapunk egy f-j-r-n-s-e-t, amiből minden második (vagy N-edik) blokk hiányzik. Ez a gyakorlat szempontjából az adatok megsemmisülésével jár, ezért a tiszta RAID0 felhasználását csak szélsőséges helyzetekben láthatjuk. Előszeretettel használják például filmek digitalizálásakor és vágásakor, vagy amikor gyorsan sok adat érkezik, amit tárolni kell, feldolgozni ráérünk később is. Hány olvasóm lehet, akinek filmstúdiója van, vagy atomokat ütköztet otthon? Na ugye.
Szélsőséges megbízhatatlansága miatt nem is említettem volna, ha a következő, szintén szélsőséges helypazarlású megoldással együtt nem lenne életképes alternatíva.
Hát, vágjunk bele, teremtsünk raid tömböt.
# mdadm --create /dev/md0 --level=raid0\
--raid-devices=2 /dev/hda5 /dev/hda6
Hát, ez nem hiszem, hogy sok meglepetést okozott. Az opciók bőbeszédűek, maguktól értetődőek, és pontosan azt csinálják, amit elvárunk tőlük. A történelmi hűség kedvéért megjegyzem, hogy ez a parancssor a lényegesen tömörebben is írható:
mdadm -C /dev/md0 -l 0 -n 2 /dev/hda[56]
Lássuk munkánk eredményét!
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md0 : active raid0 hda6[1] hda5[0]
9767296 blocks 64k chunks
unused devices: <none>
És íme, amit a kernel gondol első raid tömbünkről. Meg általában a helyzetről. Az első sorból megtudjuk, milyen raid módokat, avagy szinteket ismer a kernel. Esetünkben mind a hármat, amiről szó lesz. Ezután felsorolja a létező raid tömböket, ezeknek a neve hagyományosan /dev/mdN. Első, és ez idáig egyetlen tömbünk egy RADI0, ott a két partíció, a méret, hogy mekkora darabonként válogatja a két egységet, és hogy active, azaz használjuk bátran. Hogy lássuk, mennyivel többet gondol erről az mdadm:
# mdadm --detail /dev/md0
/dev/md0:
Version : 00.90.01
Creation Time : Tue Oct 12 23:13:34 2004
Raid Level : raid0
Array Size : 9767296 (9.31 GiB 10.00 GB)
Raid Devices : 2
Total Devices : 2
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Tue Oct 12 23:13:34 2004
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Chunk Size : 64K
UUID : e36afccd:c44c1628:d73105bd:b2bc7e7b
Events : 0.1
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 3 6 1 active sync /dev/hda6
Ez aztán jó nagy adag információ. Rögtön megtudjuk, hogy éjt nappallá téve dolgoztam ezen az irományon, hogy milyen problémák vannak a különböző bináris és decimális SI előtagokkal, és hogy a szuperblokkunk perzisztens, azaz újfajta, önismerő raid tömbünk van. Mindenesetre ebből is az derül ki, hogy a tömbünk tiszta, és használhatjuk.
Ne is habozzunk:
# mkfs.xfs /dev/md0
[...]
# mount /dev/md0 /mnt/
# df -h
Filesystem Méret Fogl. Szab. % Csatl. pont
[...]
/dev/md0 9,4G 272K 9,4G 1% /mnt
# cp /home/tudor/flim/minircfull.avi /mnt/
# df -h
Filesystem Méret Fogl. Szab. % Csatl. pont
[...]
/dev/md0 9,4G 27M 9,3G 1% /mnt
# ls -l /mnt/
összesen 27140
-rw-r--r-- 1 root root 27788540 2004-10-12 23:24 minircfull.avi
Teljesen remekül működik. Örvendezzünk.
Megérkeztünk a gyors és megbízható zónába. A lemezeket egymás mellé tesszük, és mindent, amit írunk, fölírjuk mindegyikre. Így minden adat többször is meglesz, ezért ha az egyik lemez elköltözik, akkor lesz még egy másik (több másik) példányunk.
Természetesen ez nem túl gazdaságos megoldás - egy byte adat tárolásához kettő vagy több byte diszket kell vásárolnunk. Mindenesetre a mai merevlemez-állapotok közepette, az az adat, ami egy lemezen van, az nincs. Olyan adatot, amire szükségünk van, mindig több helyen tartsunk, legyen az rendszeres mentés, vagy valamilyen raid tömb.
Az írás sebességén ez a megoldás nem javít, sőt, kicsit (IDE busz és kevés ész esetén nagyon) rontja is. Az olvasás sebességét megvalósítástól függően javíthatja, mert az olvasást szétoszthatja a diszkek között. A linux RAID1 drivere képes erre.
Ezzel együtt, a RAID1 elsősorban biztonsági megoldás, megfelelő hardver és szoftver esetén könnyen túlélhetővé tesz egy lemezhibát. A biztonsági mentést nem okvetlenül helyettesíti, de ha a két diszk nem egy helyen van, akkor már egész jól alakít. Így, ha az egyik szerverszobába beszabadul egy csákányos őrült, akkor a másik, kilométerekre lévő szerverszoba átveheti a feladatokat. Ilyen Nagy Megbízhatóságú rendszereket sokféleképpen és sokféle eszközből lehet építeni. Rátermettségtől és műszaki felkészültségtől függően kiváló eredmények érhetők el - voltak olyan osztott rendszerek, melyek kihagyás nélkül élték túl a new yorki terrortámadást. Ezeknek az ára persze a csillagos eget verdesi, de a háztartásban megtalálható eszközökből is összerakható pár tíz másodperces kihagyással működő HA rendszer.
Megismerkedünk pár új fogalommal is, ezek egyike sem ismert a RAID0 tömböknél.
3.5 Néhány fogalom
3.5.1 Szinkronizálás
Ha a szinkron bármely okból elromlik, akkor ezt valakinek helyre kell tennie. Ez RAID1 esetén annyit jelent, hogy ha az egyik diszk lemarad (például mert elromlott, és új került a helyébe), akkor a másikról át kell másolni az adatokat. Ez a diszkek méretétől és sebességétől függően igen hosszú folyamat is lehet, egy komolyabb, rosszul tervezett IDE raid tömb esetén órákig is tarthat. Elméletben a tömb ez idő alatt használható, hiszen az adataink megvannak az egyik diszken, de a rendszerbusz ilyenkor erőteljesen leterhelt, ezért megvalósítástól függően erőteljesen lelassulhat a használat.
Mondanom sem kell, a linux kernel raid megoldása ebben a versenyhelyzetben a felhasználónak kedvez. Ha a szinkronizálás alatt álló tömbre írunk, vagy arról olvasunk, akkor elveszi a sávszélességet a szinkronizálástól, és mi szinte észre sem vesszük, hogy mi történik. Az input-output teljesítmény csak pár százalékkal csökken, persze a szinkronizálás tovább fog tartani.
Más RAID rendszereknél a szinkronizálás komoly számolást is igényelhet, és ez a képessége a rendszernek olykor szűkös. Ez lehet, hogy befolyásolja, melyik raid szervezés mellett döntünk. Egy régi RAID kártya esetleg annyira megszenvedi a RAID5 szinkronizálásával járó munkát, hogy ki sem tudjuk várni.
Egy korszerű és alaposan átgondolt raid tömbben nem csak dolgozó eszközök vannak. Mivel, mint föntebb láthattuk, a folyamatosan működő diszkeknek hajlamuk van a viszonylag egyszerre elromlásra, jó, ha beillesztünk egy tartalék, avagy ,,spare" diszket. Ez nyugalmi állapotban csak ott ül és figyel. Optimális esetben áramot sem kap, és nem pörög. Ellenben, ha valaki (rendszergazda, vagy jobbik esetben automatika) észleli, hogy az egyik diszk halott, akkor azonnal leválasztja a rossz diszket, életre kelti és beilleszti a tartalékot, és nekikezd szinkronizálni.
RAID0 esetén nincsen értelmezve a tartalék diszk, RAID1 esetén pedig csak annyi előnye van, hogy addig sem pörög és kopik, amíg nem használjuk. De a RAID5 tömböknek úgy kell a tartalék diszk, mint egy falat kenyér.
A RAID0 tömbnek két állapota van, a megy és a nem megy. Egy RAID1 tömb ehhez képest maga a színes sokféleség. Lássunk ezek közül párat.
A tömbünk tiszta, ha minden diszk előírásszerűen működik. Ezen nincsen sok magyaráznivaló, azt hiszem.
A tömbünkben lehet hibás egy diszk, ilyenkor a tömb ,,működik és piszkos". Amíg közbe nem avatkozunk, addig így is marad. A beavatkozás rendszerint szoftveres (a diszket leállítani) és hardveres (kiemelni a diszket, elvinni a szeméttárolóig, beledobni, újat betenni) lépések sorozata, és azt eredményezi, hogy a raid tömb szinkronizálásba kezd.
És természetesen van olyan állapot is, amikor a tömb összeomlik, ez egy nagyon szomorú időszak.
A raid megvalósítások egyik fő különbsége, hogy ezeket a feladatokat mennyire lehet könnyen, biztonságosan, távolról elvégezni. A Linux raid drivereivel és segédprogramjaival mintaszerűen dolgozhatunk, míg a régebbi serverraid eszközök, a sata és ide raid kártyák konfigurálása újraindítást és biosban vacakolást igényel.
3.6 RAID1 kalandok
Csapjunk is bele a lecsóba, harcos lecsóbacsapó szerszámunkkal!
# mdadm --create /dev/md1 --level=raid1\
--raid-devices=2 /dev/hda5 /dev/hda6
Az eredmény valóságos tűzijáték!
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md1 : active raid1 hda6[1] hda5[0]
4883648 blocks [2/2] [UU]
[====>................] resync = 23.3% (1141056/4883648)\
finish=4.1min speed=15159K/sec
unused devices: <none>
Az előbb megfigyelten felül megtudjuk azt is, hogy a két diszkből kettő él, és hogy hogy halad a szinkronizálás művészete. Ha a watch cat /proc/mdstat parancsot adjuk ki, akkor láthatjuk is kúszni (az egyébként szabadalommal védett) bitkolbászt. Lássuk ezt az mdadm szemszögéből is:
# mdadm --detail /dev/md1
/dev/md1:
Version : 00.90.01
Creation Time : Tue Oct 12 23:40:49 2004
Raid Level : raid1
Array Size : 4883648 (4.66 GiB 5.00 GB)
Device Size : 4883648 (4.66 GiB 5.00 GB)
Raid Devices : 2
Total Devices : 2
Preferred Minor : 1
Persistence : Superblock is persistent
Update Time : Tue Oct 12 23:40:49 2004
State : clean, resyncing
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Rebuild Status : 95% complete
UUID : 26df16e7:02cf2128:daa445b3:3f587568
Events : 0.1
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 3 6 1 active sync /dev/hda6
Ő sem mond mást, a tömb tiszta, és szinkronizál. A méret sajnos fele a RAID0-nál tapasztaltaknak, de ez egy kegyetlen világ.
Hogy ezt szemléltessük, okozzunk is kárt második tömbünknek. Erre is az mdadm lesz a megfelelő eszköz, mert mindenre az a megfelelő eszköz.
# mdadm /dev/md1 --fail /dev/hda6
mdadm: set /dev/hda6 faulty in /dev/md1
Kíméletlen eljárásunknak meg is van az eredménye, a syslog tájékoztat minket a szomorú eseményről:
# cat /var/log/syslog
[...]
logfejléc: raid1: Disk failure on hda6, disabling device.
logfejléc: Operation continuing on 1 devices
logfejléc: RAID1 conf printout:
logfejléc: --- wd:1 rd:2
logfejléc: disk 0, wo:0, o:1, dev:hda5
logfejléc: disk 1, wo:1, o:0, dev:hda6
logfejléc: RAID1 conf printout:
logfejléc: --- wd:1 rd:2
logfejléc: disk 0, wo:0, o:1, dev:hda5
[...]
Ennek a sok szövegnek nagyjából az az értelme, hogy a raid1 hibát észlelt a /dev/hda6 eszközön (naná, mi mondtuk, hogy hibás - persze ez nem igaz, de egy számítógépet könnyű átverni), és ezért kiveszi a tömbből, és kiírja a műtét előtti és utáni konfigurációt. Jól láthatjuk, hogy a diszkek száma megfeleződött, és ebben megerősít minket mind a /proc/mdstat, mind a mdadm:
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md1 : active raid1 hda6[2](F) hda5[0]
4883648 blocks [2/1] [U_]
unused devices: <none>
# mdadm --detail /dev/md1
/dev/md1:
[...]
Update Time : Tue Oct 12 23:47:25 2004
State : clean, degraded
Active Devices : 1
Working Devices : 1
Failed Devices : 1
Spare Devices : 0
UUID : 26df16e7:02cf2128:daa445b3:3f587568
Events : 0.3
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 0 0 - removed
2 3 6 - faulty /dev/hda6
Egyik diagnosztikai eszközünk sem rejti véka alá, hogy a két diszkből csak egy működik. Az előbbi (F) jellel mutatja, melyik halott, az utóbbi azt is elárulja, hogy a tömbünk tiszta, de ,,degradált" (a magyar szakzsargonban inkább ,,féllábú"), és hogy a hibás eszközt lelkiekben eltávolítottuk. Fizikailag ugyan nem lehet eltávolítani egy partíciót egy diszkről (nagyon rázna), de a Nagybetűs Életben ez az az állapot, amikor a diszket ki lehet húzni, ki lehet cserélni, feltéve, ha a megfelelőt húzzuk ki. Adjunk hozzá egy új eszközt, hogy adataink biztonságban legyenek:
# mdadm /dev/md1 --add /dev/hda7
mdadm: hot added /dev/hda7
És rögtön vizsgáljuk is meg az Isaura-szerűen bonyolódó helyzetet.
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md1 : active raid1 hda7[2] hda6[3](F) hda5[0]
4883648 blocks [2/1] [U_]
[=======>.............] recovery = 36.3% (1774464/4883648)\
finish=3.5min speed=14515K/sec
Nézzük, kik vesznek részt a játékban. Régi ismerősünk /dev/hda5, mint rendesen, a helyzet magaslatán. Az új játékos, /dev/hda7 befurakodott a második helyre, kísérleteink mártírját, /dev/hda6-ot, a harmadik helyre szorítva. És eközben szinkronizálunk, mert az új játékosnak is ismernie kell az eddig történteket. Részletesebb az mdadm, és nevet is ad az eseményeknek:
# mdadm --detail /dev/md1
/dev/md1:
[...]
Raid Devices : 2
Total Devices : 3
Preferred Minor : 1
Persistence : Superblock is persistent
Update Time : Wed Oct 13 00:01:03 2004
State : clean, degraded, recovering
Active Devices : 1
Working Devices : 2
Failed Devices : 1
Spare Devices : 1
Rebuild Status : 41% complete
UUID : 26df16e7:02cf2128:daa445b3:3f587568
Events : 0.4
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 0 0 - removed
2 3 7 1 spare rebuilding /dev/hda7
3 3 6 - faulty /dev/hda6
Ebből megtudjuk, hogy az eddig két elemű tömbünk bővült egy harmadik taggal, akit tartalékként (spare devices) sorolt be, de egyből neki is látott szinkronizálni. Egy eszköz aktív (/dev/hda5), kettő dolgozik (/dev/hda5, viszi a boltot, és /dev/hda7, mert szinkronizál), egy hibás (/dev/hda6), és van egy tartalék eszközünk is, ami eddig nem volt. A tömb állapota pedig ,,tiszta, féllábú, de már elkezdett kinőni" - mi ehhez képest egy gyík a farkával? Azt is érdemes megfigyelni, hogy a ,,diszkleltárban" négy sor szerepel. Ha megfigyeljük a részleteket, nem kavarodunk össze. A második (1-es sorszámú) sor csak jelzi, hogy a tömbünk két diszkből állna, de a második diszket kiszereltük (,,removed"). A rendszer emlékszik még arra, hogy oda kell valami, és fönttartja a helyet, ezért van négy sor. Várjunk kicsit, és nézzük meg a végeredményt:
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md1 : active raid1 hda7[1] hda6[2](F) hda5[0]
4883648 blocks [2/2] [UU]
# mdadm --detail /dev/md1
/dev/md1:
[...]
Raid Devices : 2
Total Devices : 3
Preferred Minor : 1
Persistence : Superblock is persistent
Update Time : Wed Oct 13 00:06:48 2004
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 1
Spare Devices : 0
UUID : 26df16e7:02cf2128:daa445b3:3f587568
Events : 0.5
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 3 7 1 active sync /dev/hda7
2 3 6 - faulty /dev/hda6
Tulajdonképpen minden szép, a tömbünk biztonságos, de mivel a leltárnak el kell számolni a hibás eszközökkel is, tegyük helyre a sanyarú sorsú /dev/hda6-ot is:
# mdadm /dev/md1 --remove /dev/hda6
mdadm: hot removed /dev/hda6
# mdadm /dev/md1 --add /dev/hda6
mdadm: hot added /dev/hda6
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md1 : active raid1 hda6[2] hda7[1] hda5[0]
4883648 blocks [2/2] [UU]
# mdadm --detail /dev/md1
/dev/md1:
[...]
Raid Devices : 2
Total Devices : 3
Preferred Minor : 1
Persistence : Superblock is persistent
Update Time : Wed Oct 13 00:13:20 2004
State : clean
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
UUID : 26df16e7:02cf2128:daa445b3:3f587568
Events : 0.7
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 3 7 1 active sync /dev/hda7
2 3 6 - spare /dev/hda6
Amint láthatjuk, /dev/hda6 ott maradt tartaléknak, és türelmetlenül várja, hogy a másik két elem megbetegedjen. Természetesen nem kötelező bent tartani, ha csak egyszerűen elávolítjuk, akkor felhasználhatjuk más tömbökben. A hibás eszközök száma 0, két aktív eszközünk van, és az állapot ,,tiszta" - RADI1 nirvána.
Fontos apróság, hogy bár ezt nem szemléltettem, de ez idő alatt az esetlegesen fölcsatolt raid tömb teljes mértékben használható volt, sőt, az írás-olvasás sem lassult le túlságosan. A felhasználók a történtekből nem vettek észre semmit.
3.7 RAID 1 0
Ha összetesszük, amink van, jó lesz nekünk. Van gyors tömbünk, és van megbízható tömbünk - tegyük össze a kettőt, és lesz gyors és megbízható tömbünk. Matematikailag levezethető, hogy ettől még nem lesz olcsó, tehát a háromság elve nem sérül.
E megoldásnál RAID1 tömböket illesztünk össze RAID0 tömbbé. Az eképpen összerakott tömbben a rendelkezésünkre álló tömb mérete mindig a résztvevő diszkek méretének a fele. Ez ugyan pazarlás, de akár a részt vevő diszkek fele is meghalhat, mielőtt az adataink bajbakerülnének, és a sebességet is tetszés szerint növelhetjük.
A tömb felépítésekor ne felejtsük, hogy RAID1 tömbökből csinálunk RAID0-t, és nem fordítva. Ha mondjuk 3 RAID0 tömböt szerveznénk össze egy RAID1 tömbbe,, akkor egy diszk halála egy elemet szüntetne meg, három diszk halála pedig az egész rendszert megsemmisítheti. Ha 3 diszkből álló RAID1 tömbökből állítunk össze egy RAID0-t, akkor ugyanakkora területhez jutunk, de akár a diszkjeink kétharmada is tönkremehet, és mi még jók vagyunk. Hm, ezen még dolgozunk.
Ha a pénz nem számít, akkor igyekezzünk ezt a megoldást használni. No, de mi van, ha számít?
3.8 RAID10
A fontoskodó és precízkedő személyek egyik kedvenc szórakozása, hogy a nem hajszálpontosan fogalmazó embertársaikat kijavítják. Kiváló vadászterületük volt a korábban említett RAID 1 0 tömb, amit sokkal kényelmesebb ,,rédtíz"-nek mondani, de hivatalosan ,,réd egy nulla", mert végülis egy raid1 és egy raid0.
Hát, ezeknek az időknek vége. Neil Brown, egy szimpatikus úriember megalkotott egy RAID10 megoldást. Ez nekem is újdonság, most csinálok ilyet először. A fő cél nem az, hogy végre szemébe nevethessünk a minket gúnyoló elitistáknak, hanem hogy a raid megoldás választása ne legyen olyan nehéz döntés, hogy ne csak páros számú diszkből csinálhassunk gyors és megbízható tömböt. Ennek alighanem meg fog felelni, ha kiállja a sebesség és megbízhatóság próbáját.
# mdadm --create /dev/md0 --level=10 --layout=f4
-raid-disks=5 /dev/hda[56789]
VERS = 9001
mdadm: array /dev/md0 started.
vurstli:/home/tudor# cat /proc/mdstat
Personalities : [raid10]
md0 : active raid10 hda9[4]
hda8[3] hda7[2] hda6[1] hda5[0]
3664640 blocks 64K chunks 4 far-copies [5/5] [UUUUU]
[==>..................] resync = 11.7%
(430592/3664640) finish=36.3min speed=1481K/sec
Az alapelvet magam sem értem, ami nem csoda. A RAID0-hoz hasonlóan kis darabokra osztja föl a résztvevő diszkeket, és ezekből többet is tárol, különböző diszkeken. A --layout opcióban rejlik a lényeg, ugyanis a RAID10 tömb kétféle lehet. A ,,near", azaz közeli elv szerint rendezett blokkokkal az írás és az olvasás is gyorsul, mint a RAID0 esetében, de nem az egész tömbön. A ,,far", avagy távoli elv szerint az olvasás gyorsul, az írás valamelyest lassul. A működés további rejtelmei, és ezeknek az állításoknak pontosítása még hátravan. Elsőként szükségem lenne egy 5 diszkkel ellátott kísérletező gépre, de ezekből kifogytunk.
A példában szereplő parancs után, reményeim szerint egy 3.6 GB-os tömböt kapunk (5 darab 3 GB-s eszközből), amiből alighanem 3 diszket is kiemelhetünk adatvesztés nélkül. Ha ez igaz, akkor legalább egy picit megértettem, mit csinálok.
A RAID10 bizonyos korlátait, nevezetesen a (minimum) 50%-os overheadet a RAID5 hivatott eltüntetni. Ha a diszkjeinket így rendezzük, akkor N diszk esetén nem P(N/2) lesz az összes terület, hanem P(N-1). És ez olyan helyeken, ahol a tárterület iránti igény jelentős, ámde az anyagai javak halma csekély, fontos lehet.
Ennek megoldásához kell némi trükk. A diszkeken lévő adatok mellé teszünk még ellenőrző összegeket is, úgy, hogy ha egy diszk meghal, akkor annak tartalmát a többiből helyre lehessen állítani. Ezzel diszket spórolunk meg, de semmi sincs ingyen - valakinek ki kell számolnia ezeket az ellenőrző összegeket. És ez hardveres raid megoldás esetén egy nagy valószínűséggel alulméretezett kicsi processzor lesz, ezért bizonyos raid hardvereken a RAID5 irása embertelenül lassú lehet, míg az olvasás az egy diszkével egyezik meg.
Szoftveres raid esetén a helyzet rózsásabb, mert a gépek fő processzora manapság erősen túl van tervezve, ezért amíg a külvilágra (memória, diszk, hálózat, user input) vár, bátran számolgathatja ezeket az amúgy nem túl bonyolult dolgokat. A mai linuxos swraidok, közepesen tisztességes pc hardveren (IBM xseries 345) képesek gigabitnél gyorsabban írni, hiszen ha a számolgatás nem gond, akkor az írást eloszthatják a diszkek között, és 2 darab 2.8-as Xeonnak nem akadnak össze az ujjacskái ennyi számtól.
A RAID5 másik szűk keresztmetszete, hogy egy raid tömb csak egy diszk halálát viseli el. Ha bármilyen okból kettő hal meg, bajban leszünk. Nagy bajban. Ezért nagyobb RAID5 tömbökhöz célszerű tartalék diszket illeszteni.
mdadm --create /dev/md2 --level=raid5 --raid-devices=3 \
--spare-devices=1 /dev/hda[5-8]
Itt már gyárilag megadunk tartalék eszközt (egy darabot, és azt is szemléltetem, hogy shell wildcardokat bátran lehet használni. Faggassuk ki informátorainkat:
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md2 : active raid5 hda7[3] hda8[4] hda6[1] hda5[0]
9767296 blocks level 5, 64k chunk, algorithm 2 [3/2] [UU_]
[======>..............] recovery = 30.6% (1497088/4883648) \
finish=8.0min speed=7044K/sec
A szinkronizálás sebessége kevesebb, mint fele a RAID1-nél látottnak, köszönhetően annak, hogy itt most 3 ,,diszk", igazándiból partíció között számolgat a processzor. Nem mellesleg a CPU terhelése 5%, ami jelzi, hogy ez nem olyan komoly számítás. Egy érdekes apróság - a [UU_] azt mutatja, hogy csak két diszk működik. Mi lett a harmadik aktív diszkkel? Kérdezzük meg az mdadm-ot.
# mdadm --detail /dev/md2
/dev/md2:
Version : 00.90.01
Creation Time : Wed Oct 13 00:34:58 2004
Raid Level : raid5
Array Size : 9767296 (9.31 GiB 10.00 GB)
Device Size : 4883648 (4.66 GiB 5.00 GB)
Raid Devices : 3
Total Devices : 4
Preferred Minor : 2
Persistence : Superblock is persistent
Update Time : Wed Oct 13 00:34:58 2004
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 4
Failed Devices : 0
Spare Devices : 2
Layout : left-symmetric
Chunk Size : 64K
Rebuild Status : 33% complete
UUID : 95f07e1a:6d40ecab:b4dc195e:68113cfa
Events : 0.1
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 3 6 1 active sync /dev/hda6
2 0 0 - removed
3 3 7 2 spare rebuilding /dev/hda7
4 3 8 - spare /dev/hda8
A tömb tényleg csak két aktív eszközzel indult neki a nagybetűs életnek, azaz ,,féllábon". A másik kettőből egyet betett tartaléknak, egyet pedig azonnal beillesztett a féllábú tömbbe, és így szinkronizál. Ennek annak idején utánanéztem a dokumentációban (igen, a hír igaz, sokat segít, érdemes otthon is kipróbálni). Állítólag így gyorsabb az első szinkronizáció. Lehet enélkül is, józan paraszti ésszel indítani, és valóban lassabb lesz úgy. Körülbelül 10%-al. Ezen múlhat emberélet, végülis, de inkább csak James Bond filmekben.
Szerencsére ez csak elméleti spekuláció, mert a tömb azonnal használható, és nagyon szépen működik. Várjuk meg, amíg befejezi a kezdeti szöszmötölést, és tekintsük meg teljes pompájában:
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md2 : active raid5 hda7[2] hda8[3] hda6[1] hda5[0]
9767296 blocks level 5, 64k chunk, algorithm 2 [3/3] [UUU]
# mdadm --detail /dev/md2
/dev/md2:
[...]
State : clean
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 64K
UUID : 95f07e1a:6d40ecab:b4dc195e:68113cfa
Events : 0.10
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 3 6 1 active sync /dev/hda6
2 3 7 2 active sync /dev/hda7
3 3 8 - spare /dev/hda8
Bátran állíthatom, semmi különöset nem látunk - 3 aktív, és egy tartalék diszk. Érdemes megfigyelni, hogy bár a /proc/mdstat-ban van egérmozi, nem árulja el egyértelműen, melyik a tartalék eszköz. Mindenesetre ez a helyzet olyan szép, hogy rögtön tegyük is tönkre:
# mdadm /dev/md2 --fail /dev/hda5
mdadm: set /dev/hda5 faulty in /dev/md2
És rögtön be is indulnak a védelmi reakciók:
logfejléc: raid5: Disk failure on hda5, disabling device.
Operation continuing on 2 devices
logfejléc: RAID5 conf printout:
logfejléc: --- rd:3 wd:2 fd:1
logfejléc: disk 0, o:0, dev:hda5
logfejléc: disk 1, o:1, dev:hda6
logfejléc: disk 2, o:1, dev:hda7
logfejléc: RAID5 conf printout:
logfejléc: --- rd:3 wd:2 fd:1
logfejléc: disk 1, o:1, dev:hda6
logfejléc: disk 2, o:1, dev:hda7
logfejléc: RAID5 conf printout:
logfejléc: --- rd:3 wd:2 fd:1
logfejléc: disk 0, o:1, dev:hda8
logfejléc: disk 1, o:1, dev:hda6
logfejléc: disk 2, o:1, dev:hda7
logfejléc: md: syncing RAID array md2
Itt két lépést is láthatunk. Először eltávolítja a /dev/hda5-öt, amitől két elemű lesz a tömb, majd rögtön utána beilleszti a /dev/hda8-at, és elkezd szinkronizálni. Ebben megerősít minket két informátorunk is:
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md2 : active raid5 hda7[2] hda8[3] hda6[1] hda5[4](F)
9767296 blocks level 5, 64k chunk, algorithm 2 [3/2] [_UU]
[==>..................] recovery = 12.0% \
(591744/4883648) finish=10.1min speed=7048K/sec
# mdadm --detail /dev/md2
/dev/md2:
[...]
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 1
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 64K
Rebuild Status : 14% complete
UUID : 95f07e1a:6d40ecab:b4dc195e:68113cfa
Events : 0.11
Number Major Minor RaidDevice State
0 0 0 - removed
1 3 6 1 active sync /dev/hda6
2 3 7 2 active sync /dev/hda7
3 3 8 0 spare rebuilding /dev/hda8
4 3 5 - faulty /dev/hda5
Ne felejtsük el, most veszélyben vagyunk. Annak ellenére, hogy szinkronizálás közben gond, és számottevő lassulás nélkül használhatjuk a tömbünket, ha még egy diszk meghal, akkor nagy bajba kerülünk. Kerüljünk hát nagy bajba:
# mdadm /dev/md2 --fail /dev/hda7
# cp /home/tudor/flim/caravana.wmv /mnt/
cp: nem lehet létrehozni a következő reguláris fájlt:
`/mnt/caravana.wmv': Be/kimeneti hiba
Így néz ki a nagy baj. Ha ezt a Nagybetűs Életben látjuk, akkor föl kell készülnünk egy, a szőnyeg peremén előadott mentegetőzésre. Tulajdonképpen nem is tehetünk mást, mint hogy elővesszük a széfből a tegnapi mentést, és bánatunkat sörbe fojtjuk. Ezt annak ellenére, hogy informátoraink optimisták,
és arcukon egy szebb jövő fénye tükröződik:
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md2 : active raid5 hda7[3](F) hda8[4] hda6[1] hda5[5](F)
9767296 blocks level 5, 64k chunk, algorithm 2 [3/1] [_U_]
resync=DELAYED
Vár a csodára, hogy az utoljára eltávozott eszköz még visszatér, és addig is késlelteti az újraszinkronizálást. Ez nem fog megtörténni, a tömbünk elment a szemétbe. Fontos tudni, hogy amíg ezt meg nem mondjuk a tömbnek, nem fogja elhinni, amilyen makacs.
# mdadm --stop /dev/md2
Amíg ezt nem mondjuk neki, pár másodpercenként nekiveselkedik a szinkronizálásnak - ami ugyan nem fog sikerülni, de közben kiválóan megtömi a logokat.
Mit próbálhatunk tenni mégis? Nem kívánom a hamis remény kicsiny lángját ültetni az éppen csomagoló rendszergazdák szívébe, de természetesen van innen is kiút. Az mdadm is rendelkezik helyreállító móddal, és én már láttam olyat, hogy valaki létfontosságú raid tömböt hexaeditorral megmentett (igen, Fujinak kellene írnia ezt az irományt, de nem ér rá, mert csinálja - én addig tanítom), de jobb az elővigyázatosság. Menteni, menteni, menteni - ezt megmondotta volt már Lenin elvtárs is.
4 Elmélet és gyakorlat
Elméletben semmilyen különbség nincsen elmélet és gyakorlat között. De gyakorlatban... Nincs ez máshogy a raid tömbökkel sem. A hardver, a sanyarú valóság megakadályozhatja a tetszőlegesen nagy sebesség, vagy a tetszőlegesen nagy tárterület elérését. Lássunk párat a gyakori gondok közül.
4.1 IDE vezérlők
Az átlag desktop PC-ben kettő IDE vezérlő van. Ezek mindegyikére két diszket (cdt, cdírót, dvdt, Zip lemezt, akármit) illeszthetünk. Kézenfekvő megoldás, hogy az egyikre tesszük a cdt, a másikra két merevlemezt, raid1, és örülünk. A gép meg lassú, mint a teve. Mi történhetett?
Az IDE vezérlő sajnos igen buta. Az évek során a beépített hibák száma nőtt, a butaságoké dettó. Egyik legnagyobb gond vele, hogy ha egy vezérlőn két eszköz van, akkor a rendelkezésükre álló sávszélesség nem az eredeti fele lesz, hanem ütközések, tervezési hibák, DMA hibák miatt jóval kevesebb. Főleg RAID1 szervezés esetén, ahol a párhuzamos írás a történet lelke. Kerüljük ezt a balesetet.
Áttesszük hát az egyik diszket a cdvel közös vezérlőre. És látjuk a távolban a reumás csigák felverte por kicsiny csíkját. Mi történhetett?
Az IDE vezérlő egy másik nyavalyája, hogy konzervatív. Ha két, különböző sebességű eszköz van egy vezérlőn, akkor beáll a lassabb sebességére. És mivel az egész tömb sebessége mindig a leglassabb elem sebessége lesz, kész a baj. Bizony, ha mindenáron IDE diszkekből építünk raidot, telepítés után szedjük ki a régi lassú cdolvasót, és ha mindenáron muszáj, tegyünk bele egy újabbat, fürgébbet. Hozzá kell tennem, hogy az újabb IDE vezérlők ezt a hibát már nem követik el, de cserébe a következő sokkal inkább érvényes rájuk.
Új rendszerünket megtisztítottuk minden gyanús 2x cdromtól. Megcserdítjük bitkorbácsunkat, és a pompásnak gondolt paripa békés ökrösszekérként cammog az információs szupersztrádán. Mi történhetett?
Sajnos az IDE vezérlők nem csak buták is, általában nem is teljesen szabványosak. Az optimális teljesítményhez sokmindent be kell állítani, amihez megfelelő meghajtóprogramok kellenek. Ezeket ne felejtsük el telepíteni (Windowsra), a kernelbe belefordítani (Linuxra), megírni. Néha az is megesik, hogy ezeket nem tudja magától beállítani az operációs rendszer, ilyenkor ezt se felejtsük el. Linuxon a hdparm nevű program segít ebben.
Ha ezt a három hibát nem követjük el, általában egész fürge szoftveres raid tömbünk lesz. De sokszor találunk ,,szerver" alaplapokon ,,IDE-RAID" vezérlőket.
4.2 IDE RAID vezérlők
Jómagam ezt sosem teszteltem, de megbízható forrásokból tudom, hogy ezeknek jó része ugyanúgy szoftveres raid, mint ami például a Linux kernelben is van, csak a drivert a firmware-be töltjük - ugyanúgy a rendszerprocesszort használja számolásra, és ugyanúgy a rendszerbuszon át hömpölyög az adat. Minden szempontból célszerűbb ezeket külön IDE vezérlőként kezelni, egy-egy diszket rájukdugni, és elolvasni a RAID-HOGYAN-t. Gyorsabb, rugalmasabb, megbízhatóbb tömbünk lesz. Egy friss mérés szerint 142 ezer forintból egy 420 Gbyteos RAID5 tömb rakható össze, és átlagosan 40 Mbyte/sec írási/olvasási sebességet érhetünk el vele.
Gondolom, senkit sem lep meg, hogy léteznek drága és jó IDE és SATA RAID vezérlők, de ha már sokat költünk, akkor vásárolhatunk scsi-t is. Azon ritka alkalmakkor van haszna ezeknek, ha 30 darab 200 gigás SATA diszket akarunk valahová bepakolni.
4.3 SCSI RAID vezérlők
Itt a kép jóval tarkább. Léteznek gyors, megbízható és drága eszközök, ezek olykor beválhatnak, és fellendíthetik életminőségünket. Léteznek lassú, megbízhatatlan, és olcsó eszközök is, ezekből valahogy több van. Az élet persze sosem egyszerű - saját szememmel láttam drága, lassú és megbízhatatlan raidvezérlőt, ami ráadásul azt hazudta a rendszernek, hogy nincs diszkhiba, és folyamatosan dolgozott a hibás diszkkel. Csúf eset volt. Ráadaásul egy ilyen kártya nem is repül szépen, rossz az aerodinamikája.
4.4 Hardveres vagy szoftveres RAID?
Ez örök kérdés, és aki még nem használt Linux swraidet, elég gyakran föl is teszi. Egyszerű válasz nincs, hacsak az nem, hogy 42.
Természetes, hogy a teljesítményskála alsó végén a szoftveres megoldást kedveljük. IDE/SATA merevlemezek, vagy éppenséggel USB egységekhez nem is nagyon van raid hardver. Az is magától értetődik, hogy a több tucat terabyteos, vagy nagyobb tárterületeket célhardverrel, drága storage eszközökkel oldjuk meg. A tulajdonképpeni kérdés, hogy a két szélsőség között hol húzódik a határ?
Ha figyelmen kívül hagyjuk, hogy a nagy storage eszközök képesek elég speciális műveletekre is (snapshot, állandó ellenőrzés, redundáns hozzáférés, gyors bővítés - tulajdonképpen jó részük megoldható linuxszal), akkor a határ most valahol az egyszámjegyű terabyteoknál húzódik. Ekkora tárterületet lényegesen olcsóbban, és legalább olyan funkciógazdagon öszerakhatunk akár lintel eszközökkel is. Ennél több diszk például már fizikailag nem fér be egy akármilyen nagy PC házba, vagy a kábelek lennének túl hosszúak, vagy elfogy a rendszerbusz sávszélessége. De ez mozgó cél, az új rendszerbuszok lendíthetnek ezen, az ,,olcsó" (=SATA) diszkek is egyre nagyobbak.
Figure 5: Raid megoldások összehasonlítása
| Gép | Típus | Diszkvez. | Diszk | Írás | Olvasás | Átlag |
| sziszi | x345 | qla2340/r5-8 | cx700 | 85 | 127 | 106 |
| sziszi | x345 | qla2340/r5-4 | cx700 | 68 | 120 | 94 |
| sziszi | x345 | fusion/swr5 | 10k/320 | 75 | 110 | 93 |
| rserver | x345 | qla2340/r5-8 | cx700 | 67 | 116 | 91 |
| hera | x335 | fusion/swr1 | 15k/320 | 72 | 75 | 74 |
| noc | x330 | aic7892/swr1 | 10k/160 | 44 | 53 | 49 |
| rserver | x345 | fusion/swr1 | 10k/160 | 26 | 40 | 33 |
| gaia | x235 | ibm5i/r5 | 10k/160 | 32 | 26 | 29 |
| rserver | x345 | ibm5i/r5 | 10k/160 | 12 | 30 | 21 |
| hera | x340 | ibm4l | 10k/160 | 13 | 25 | 19 |
A táblázat pár, Gödöllőn megfordult és elszenvedett valós esetet mutat be, jobbára Lajber Zoltán kollégámnak köszönhetjük.
Figyelemre méltó, hogy a pár száz dolláros hardveres raid kártyák kivétel nélkül legalul vannak, ami kiválóan aláhúzza az eddig elmondottakat. Az is érdekes, hogy az rserver teljesítménye 50%-al nőtt amikor kidobtuk a vezérlőkártyát (ez volt az a bizonyos hazudós, szalagról állítottuk vissza az adatokat).
Az élmezőny megoszlása sem tanulság nélkül való. Három adattal szerepel a storage eszközünk, és egy adattal egy szoftverraid. Különösebb erőfeszítés nélkül fölveszi a versenyt a sokkal drágább storage tömbbel - sebesség dolgában. A két rackunit magas x345-be nem tudunk beletömni 4 terabyte diszket, sajnos.
5 Logikus Űrméret Ügyvezető
Elnézést a címért, de az LVM, azaz Logical Volume Manager elnevezés magyar fordításával mindeddig adós a nyelvészet, és a Linuxvilág magazin is. Az első probléma, elmagyarázni, miről is van szó. Sokszor kerültem már abba a helyzetbe, hogy erre szükség volt, és mindig ugyanúgy vágtam ki magamat belőle, és az LVM Howto is ez irányba tapogatózik.
A Volume Management a mindenki által ismert partíció fogalmának alapos általánosítása. Ez természetesen nem igaz - eredetileg a partíció volt a Volume Management egy alapos leegyszerűsítése, az akkor bimbózó, és a FAT filerendszer korlátaiba fájdalmasan beleütköző Intel/MSDOS páros számára. A ,,fizikai" partíciókkal, kötetekkel, volume-okkal (tetszés szerint) ellentétben a ,,logikai" köteteket tetszés szerint átméretezhetjük, mozgathatjuk, készíthetünk pillanatfelvételeket, titkosíthatjuk.
A számítástechnika történetében nem ez az első ilyen megoldás, minden nagyobb operációs rendszerhez tartozik valami hasonló. Az IBM megoldása, az EVMS (Enterprise Volume Management System) egyesíti magában mindazt, amit eddig elmondtam a raid tömbökről, és azt, amit hamarosan el fogok mondani az LVMről. Mindezt az IBMtől megszokott finom megalomániával és kecses nehézkességgel. Azért említettem meg mégis, mert az EVMS használható Linux kernellel is, és sokan esküsznek rá. Én maradok a jól bevált, natív linuxos eszközöknél.
Egy működő LVM rendszer 3 alapvető alkotóelemből áll, mindegyik elem szerepe, szerintem világos és egyszerű. Használatukhoz természetesen kell a kernelbe LVM (2.6-os sorozatban Device Mapper) támogatás, és az lvm10, 2.6-os sorzatú kernelhez az lvm2 programcsomag.
5.1 Fizikai kötet
Avagy Physical Volume, PV. Ezek a gyermekkorunkból ismert diszkek, partíciók, RAID tömbök, általában blokkeszközök, amelyeket szeretnénk az LVM-be beilleszteni. Tulajdonképpen bármilyen blokkeszköz lehet PV. Érdekes viselkedést várhatunk el egy UDMA33-as diszkekből összeillesztett raid1, 8 usb drive és két ENBD (lásd ott) eszközből összeeszkábált LVM rendszertől, ennek nincsen akadálya, ha az ápolókat nem zavarja. Nincs is sok dolgunk vele, csak megmondjuk egy blokkeszköznek, hogy ő mostantól PV, a fantáziadús nevű pvcreate paranccsal:
# pvcreate /dev/md0
Physical volume "/dev/md0" successfully created
Hasonlóan bonyolult a rendelkezésünkre álló PV-k listáját előkeríteni:
# pvdisplay
--- NEW Physical volume ---
PV Name /dev/md0
VG Name
PV Size 3,49 GB
Allocatable NO
PE Size (KByte) 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID 4PKa62-0tDG-yj4B-gBEq-7aSW-FgaJ-4KXUY3
Láthatjuk, hogy egy új PV-vel van dolgunk, 3.49 GB méretűvel, amely még nem tartozik VG-hez. Hogy mihez?
5.2 Kötetcsoport
Avagy Volume Group, VG. A pályázatokon beszerzett, karácsonykor ajándékba kapott, rablóhadjáratokon összeharácsolt PV-k összességét nevezzük VG-nek, azaz egy VG több PV-ből állhat. A VG-ben fölhalmozott byteokat fogjuk később kiosztani különböző célokra. Hogyan hozunk létre egy VG-t?
# vgcreate teszt /dev/md0
Volume group "teszt" successfully created
Meg kell adni egy nevet a csoportnak, és fel kell sorolni a benne részt vevő PV-ket. Természetesen ez a lista nem végleges, létezik vgextend, hogy bővíthessük a csoportot,vgreduce parancs is, hogy csökkenthessük (bár ekkor nem árt gondoskodni az adatokról), és egy sereg más hasznos kis eszköz.
# vgdisplay
--- Volume group ---
VG Name teszt
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size 3,49 GB
PE Size 4,00 MB
Total PE 894
Alloc PE / Size 0 / 0
Free PE / Size 894 / 3,49 GB
VG UUID HXYnAK-7iFQ-EWnR-7Xoq-Jou1-L2Gk-lxTyLy
Láthatjuk ,,teszt" nevű kötetcsoportunkat, összes lényeges adatával. Láthatjuk a nevét, a típusát (lvm2 - nagy rajongója vagyok a 2.6-os kernelsorozatnak), méretét, és hogy mennyit osztottunk ki belőle. A méretadatokat PE-ben is látjuk, ami a Physical Extent rövidítése. Nincsen semmi titok benne - nem byteonként osztjuk ki a területet, hanem PE méretű blokkokban, és minden, később tárgyalandó méretet erre kerekít az LVM. Ha leellenőrizzük a PV adatait, láthatjuk, hogy sok mezőt csak most töltött ki:
# pvdisplay
--- Physical volume ---
PV Name /dev/md0
VG Name teszt
PV Size 3,49 GB / not usable 0
Allocatable yes
PE Size (KByte) 4096
Total PE 894
Free PE 894
Allocated PE 0
PV UUID 4PKa62-0tDG-yj4B-gBEq-7aSW-FgaJ-4KXUY3
Ennyi viszontagság után nincs is más hátra, minthogy hozzájussunk végre az első felhasználható lemezterülethez.
5.3 Logikai kötet
Avagy Logical Volume, LV. Ez az, amit mostantól partíció helyett használunk. Kicsit rögösebb úton jutottunk el hozzá, mint megszoktuk, de itt vagyunk, hozzunk is létre egyet.
# lvcreate -n elso -L 1G teszt
Logical volume "elso" created
A -n opcióval adjuk meg az LV nevét, és a továbbiakban /dev/VG-neve/LV-neve módon hivatkozunk rá, esetünkben /dev/teszt/elso lesz a neve. Gyűjtsünk be egy kis információt:
# lvdisplay
--- Logical volume ---
LV Name /dev/teszt/elso
VG Name teszt
LV UUID D7ZxOs-H2aY-T7nR-zj8K-CttH-llT4-zHSlCN
LV Write Access read/write
LV Status available
# open 0
LV Size 1,00 GB
Current LE 256
Segments 1
Allocation inherit
Read ahead sectors 0
Block device 254:0
Senkit semmilyen meglepetés nem ért, van egy 1 GB méretű blokkeszközünk.
# vgdisplay
--- Volume group ---
VG Name teszt
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 2
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size 3,49 GB
PE Size 4,00 MB
Total PE 894
Alloc PE / Size 256 / 1,00 GB
Free PE / Size 638 / 2,49 GB
VG UUID HXYnAK-7iFQ-EWnR-7Xoq-Jou1-L2Gk-lxTyLy
És itt is kevés meglepetéssel találkozunk. 1 GB kiosztva, marad 2.5 GB, és van egy LV. Műveljük hát meg a mi földünket, miként az Írás mondja.
# mkfs.xfs /dev/teszt/elso
meta-data=/dev/teszt/elso isize=256 agcount=8, agsize=32768 blks
= sectsz=512
...
# mount /dev/teszt/elso /mnt/
# df -h
Filesystem Méret Fogl. Szab. % Csatl. pont
...
/dev/mapper/teszt-elso 1014M 144K 1014M 1% /mnt
...
Megtörölhetjük verejtékes homlokunkat, a felhasználók serege nekiláthat pakolni a fájlokat. Hozzuk létre az összes szükséges partíciót, formázzuk, mountoljuk, írjuk be az fstabba, amit ilyenkor kell. Arról a kernel és az LVM gondoskodik, hogy bootoláskor is jelen legyenek a kötetek. Azt sajnos nem tudja még, hogy bootoljon is LVről, hiszen egy bonyolultabb kötetrendszeren az egyes fájlok helye sosem köthető biztosan egy diszk egy adott szektorához, de ezen kívül mindenre jó. Mindenki boldog, szőrük fényes, fülük tiszta - amikor derült égből villámcsapás. Elfogyott a hely a partíción!
5.4 Növekedés
Tulajdonképpen ez a legegyszerűbb eljárás, amit az LVM-el művelhetünk, ennek megfelelően ez a leggyakrabban használt is. Igazán akkor kényelmes, ha olyan fájlrendszer használunk, ami online növelhető, azaz nem kell lecsatolni ehhez. Ilyen például az xfs, jfs, reiser4, nem ilyen például az ext3 vagy ext2. Lássuk hogy néz ki ez xfs-el:
# lvextend -L +389M /dev/teszt/elso
Rounding up size to full physical extent 392,00 MB
Extending logical volume elso to 1,38 GB
Logical volume elso successfully resized
Amint látjuk, az lvextend parancs megérti a rövidítéseket és nem abszolút számokat is, és most láthatjuk is, hogy hogyan kerekít PE-méretre az LVM. És, természetesen, fölfelé kerekít. Most még csak a blokkeszköz (leánykori nevén partíció) mérete növekedett, a filerendszeré nem.
# xfs_growfs /dev/teszt/elso
...
data blocks changed from 262144 to 362496
És íme, rögtön több helye van a kedves felhasználóknak:
# df -h
Filesystem Méret Fogl. Szab. % Csatl. pont
...
/dev/mapper/teszt-elso 1,4G 208K 1,4G 1% /mnt
...
Ilyen egyszerű ez. Lássunk egy kicsivel összetettebb példát is az LVM hasznosságára.
5.5 Variációk - mentés
Gyakori igény, hogy teljes mentést csináljunk egy partícióról, ahol eközben zajlik az élet, például egy adatbázis kaparja fájljait, felhasználók írják regényüket, stb. Az élet zajlása miatt könnyen előfordulhat, hogy például egy éppen mentés alatt álló fájlnak csak a fele kerül föl, vagy fölkerül a fájl, de a kísérő információk nem annyira - tulajdonképpen egy modern naplózó fájlrendszer elég érdekesen tud reagálni egy rosszkor indított mentésre, és minden végkimenetel elképzelhető. Az legkevésbé, hogy bármire megyünk a mentésünkkel.
Van erre megoldás, az xfs esetén például xfs_freeze a parancs neve. Ez leállít minden írási kísérletet, a folyamatban lévő műveleteket befejezi, és már készülhet is a mentés. Az adatbázis, illetve a kedves felhasználó pedig vár, amíg be nem fejezzük a mentést. Ez nem az az eljárás, amivel az adatbázisok vagy felhasználók jóindulatát meg lehet nyerni, egyáltalán nem. Legnagyobb sajnálatomra az XFS éppen nem akar tökéletesen együttműködni az LVM-el, és én már kicsit fáradt vagyok a teszteléshez, úgyhogy most ext3 filerendszerrel oldjuk meg.
A széles körben bevált eljárás az, hogy készítünk egy "pillanatfelvételt" az adott eszközről, és ezt mentjük, míg a menetk özben érkező írási kísérleteket feljegyezzük valahová, majd, mikor a mentéssel végeztünk, átmásoljuk ezeket. A mentés ideje alatt az érkező olvasási kísérleteket vagy a pillanatfelvételről szolgáljuk ki, vagy ha az adott fájl már változott, akkor az ideiglenes feljegyzésekből olvasunk.
Ez a gyakorlatban úgy néz ki, hogy minden blokkról megjegyezzük, ha írtak bele a pillanatfelvétel készülte óta, és a megváltozott blokkokat tároljuk valahol. És ezt természetesen LVM-el is meg tudjuk csinálni. Nem is kell neki más információ, mint egy név, amivel a pillanatfelvételre hivatkozhatunk, és némi hely, ahová a megváltozott blokkokat eltehetjük, ideiglenesen. Ennek a helynek a mérete az az apró, de fontos részlet, amin birodalmak sorsa bukhat el, ugyanis ha ez a hely megtelik, akkor kezdhetjük elölről a mentést, egy új, nagyobb tárolóhely kialakításával. Lássuk hát ezt a gyakorlatban:
6 Magunkon kívül
Mint korábban láthattuk, az egy gépben elhelyezett több diszk korlátozott megbízhatóságot ad. A rejtett paraméterek is azirányba hatnak, hogy egy reggel bekapcsolva a gépet, csak a számítófüst keskeny csíkját lássuk, márpedig ha egyszer kimegy a számítógépből a számítófüst, akkor többet nem fog számítani. Dézsaállványnak meg kicsit drága.
Ezért igyekezzünk az adatokat fizikailag is különböző helyeken tárolni. Erre jó megoldás a Sziklás Hegységben ásott 2 kilométeres betonbunker, ahová hetente két konvoj viszi a mágnesszalagokat, de nekünk erre nem futja. Vásárolhatunk sok pénzért storage eszközöket, speciális célszoftverrel, amelyek két, egymástól távolabb lévő gép között megoldják a szinkronizálást. Potom pár millióból ki is jön. Euróból, nem forintból.
És természetesen van lehetőségünk arra is, hogy józan eszünket, a mérhetetlen mennyiségben rendelkezésünkre álló szabad szoftvereket, és homlokunk verítékét használva csodát tegyünk. Lássunk erre egy egyszerűbb példát.
6.1 A feladat
Van egy szerverünk, amelyen valamilyen létfontosságú alkalmazás - ftp szerver, adatbázisszerver, könyvelés, szerződések tára, akármi - gyűjtögeti szintén létfontosságú adatainkat. A szerver a szerverszobában van, az adatok RAID1 tömbön, de mi mégsem érezzük magunkat biztonságban. A biztonsági őr szeme fényesedik kicsit mostanság? Vagy kollégánk kérdez túl sokat a pc házak és a csákányok kapcsolatát illetően? Mindenesetre fölvesszük a kapcsolatot egy erre szakosodott gyártóval, meghallgatjuk jutányos ajánlatát, úgy éves fizetésünk kétszázszorosának magasságában, udvariasan elköszönünk tőle, és elmegyünk biliárdozni a haverokkal.
Azért a gondolat nem hagy minket nyugodni, főleg, hogy a biztonsági őr anarchista röplapokat osztogat, és a fejlesztő kolléga az asztala mellett élezi a jatagánt. Nekilátunk hát a feladatnak. Megpróbáljuk megoldani, hogy létfontosságú adataink több helyen legyenek jelen, egymástól biztonságos távolságra, és úgy, hogy állandó szinkronban legyenek. Ennek a hivatalos marketingneve ,,földrajzilag elosztott raid tömb". Főbb részfeladataink a következők:
- Beszerezni egy tartalék gépet, megfelelő méretű merevlemezzel
- Kapcsolatot teremteni a két gép között
- Létrehozni mindkét gépen a szolgáltatást, a közös merevlemez használatával
- Gondoskodni arról, hogy sose írjanak egyszerre a közös területre
Az első és az utolsó részfeladat összetett, bonyolult, és önálló előadássorozatot érdemelne mindkettő. A harmadik most nem érint minket, mert nem specifikáltuk a szolgáltatást. Lássuk hát a másodikra adott válaszunkat.
Az első és legfontosabb probléma, hogy hogyan kössük össze a távoli merevlemezt a közeli géppel. A lehetőségek köre számtalan, például sűrűn forduló motoros futárok, ami nem túl praktikus, nagyon hosszú SCSI/IDE kábelek (tulajdonképpen az üvegszálas, FC merevlemezekkel több kilométeres távok legyőzhetőek), vagy valamilyen hálózati protokoll segítségével, izmos TCP/IP összeköttetés révén. Utóbbira is létezik pár megoldás, például az iSCSI, az SCSI protokoll IP-be csomagolva, vagy az ENBD, ami egy teljesen szabad forráskódú, alulról építkező és minimalista megoldás. Hogy, hogy nem, én ez utóbbit fogom ismertetni.
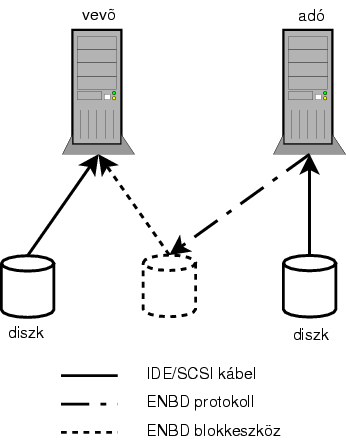 Figure 6: ENBD elvi vázlata
Az ábra sajnos elég ügyetlen, és pont a lényeg nem látszik rajta. Az ENBD, csakúgy, mint az igen rugalmas szoftverraid, annak köszönheti létét, hogy a Linux kernelben magas szinten egységes a blokkeszköz fogalma. Az ENBD (Enhanced Network Block Device) nem tesz mást, mint hogy szimulál egy blokkeszközt (az ábrán pontozott vonallal jelölt henger), amihez az adatokat a távoli gépen futó kicsiny ,,kiszolgáló" adja. A kettő között egy szép, tiszta, tűzfalazható, kezelhető TCP/IP adatfolyam (később kiderül, kb. fél tucat adatfolyam) áramlik.
Tisztázzunk egy nevezéktani zavart. A ,,kiszolgáló" szó nekem nem tetszik, pláne nem a ,,kliens". Én ,,adó" néven emlegetem a továbbiakban azt a gépet, ahol az erőforrás van, és ,,vevő" lesz a neve annak, amelyik ezt megpróbálja használni.
Lássuk röviden, hogyan kell összeállítani. Ezt a részt ömlesztve másolom egy másik, kifejezetten erről szóló írásomból ollózóm, így lehet, hogy lesz némi kavar az eszközök nevével.
Figure 6: ENBD elvi vázlata
Az ábra sajnos elég ügyetlen, és pont a lényeg nem látszik rajta. Az ENBD, csakúgy, mint az igen rugalmas szoftverraid, annak köszönheti létét, hogy a Linux kernelben magas szinten egységes a blokkeszköz fogalma. Az ENBD (Enhanced Network Block Device) nem tesz mást, mint hogy szimulál egy blokkeszközt (az ábrán pontozott vonallal jelölt henger), amihez az adatokat a távoli gépen futó kicsiny ,,kiszolgáló" adja. A kettő között egy szép, tiszta, tűzfalazható, kezelhető TCP/IP adatfolyam (később kiderül, kb. fél tucat adatfolyam) áramlik.
Tisztázzunk egy nevezéktani zavart. A ,,kiszolgáló" szó nekem nem tetszik, pláne nem a ,,kliens". Én ,,adó" néven emlegetem a továbbiakban azt a gépet, ahol az erőforrás van, és ,,vevő" lesz a neve annak, amelyik ezt megpróbálja használni.
Lássuk röviden, hogyan kell összeállítani. Ezt a részt ömlesztve másolom egy másik, kifejezetten erről szóló írásomból ollózóm, így lehet, hogy lesz némi kavar az eszközök nevével.
6.3 Installálás
A folyamat főbb lépései: kernelfordítás, segítő programok forgatása, konfiguráció. A feladatok különböznek adó és vevő oldalról. Természetesen a vevőt kell alaposaban kézbevenni.
6.3.1 Előkészületek
Kell hozzá kernel, enbd-forrás, kernelfordításhoz szükséges felszerelések. Amikor ezzel szórakoztam, a 2.4.32 volt a fejlődésben lévő verzió, és ez már együttműködik a 2.6 sorozatú kernelekkel.
- Kernel kicsomagolása
- ftp://oboe.it.uc3m.es/pub/Programs/enbd-2.4.32pre.tgz
- A kernelt meg kell foltozni. A 2.6 mellé nem lehet ,,kívülről" modult fordítani, illetve az ENBD fejlesztője nem tudja, hogyan kell.
/usr/src/linux-2.6.8.1# patch -p1 < \
../nbd-2.4.32/kernel/patches/enbd-2.6.8.pat
- Kernelkonfiguráció. A drivert a Device Drivers - Block Devices szekcióban találjuk. Ne higyjünk a sziréndaloknak, nem hajlandó nem modulként fordulni. Az IOCTL supportot is fordítsuk bele, az XFS panaszkodik, ha nincsen. Valamint ne fordítsuk be mellé fixen az NBD-t, mert összevesznek a 43-as major számon. Arra is ügyeljünk, hogy ez a kernel a vevőre kerül, ennek megfelelően állítsuk be.
- ENBD konfiguráció. Nem bonyolult, kedvenc szövegszerkesztőnkkel megeditáljuk az enbd forrás Makefile-ját, különös tekintettel a kernelforrás helyére, és hogy több processzoros-e a vevő. Az adó nem érdekel minket. Ha nem Debian rendszeren vagyunk, be kell állítani a munkakönyvtárat is, ami alapértelmezés szerint a /tmp.
- Kernelfordítás. Ez Debianban egyszerű, nem Debianban ne felejtkezzünk el a modulok megfelelő helyre másolásáról.
- ENBD fordítás. Debianban ./debian/rules binary. Nem Debianban
make configure; make;, ha jól emlékszem. A munkakönyvtárban találjuk a binárisokat.
Töröljük meg verejtékes homlokunkat, és az enbd binárisokat másoljuk az adóra, a binárisokat és a kernelt a vevőre. Debian esetén telepítsük a keletkezett enbd csomagot, és legyünk büszkék magunkra.
- Az adóra kellenek az enbd-server és enbd-sstatd binárisok.
- /etc/enbd.conf konfigurációs file. Utóbbi nem túl bonyolult szerkezetű valami, példasor:
server elso 1234 /home/tudor/melo/raiddoksi/raid1.bin -b 512
- A server szócska nem lep meg senkit, hiszen az adón az enbd szerver fut majd.
- Második paraméterünk az azonosítót tartalmazza. Ez csöppnyi magyarázatot igényel, lásd később.
- A port, melyen át elérjük.
- A megosztandó erőforrás. Lehet fájl, vagy blokk-eszköz. Esetemben egy 5 gigabyteos fájl,
- Egyéb opciók. Például az xfs egészségtelenül reagál a nem 512 byteos blokkméretre...
A szervernek van egy neve, ezzel mutatkozik be a kliensnek, és ezen tartja nyilván őt minden szereplő. Megszakadás esetén is ezt kérdezik először. Ha nem adunk meg ilyet, akkor kitalál egyet magának, véletlenszerűt. Jobb a békesség.
- Kell legyen egy /var/state/nbd könyvtár, ahová jegyzetel a szerver.
- Kell egy bejegyzés bejegyzés a /etc/services fájlba:
enbd-cstatd 5051/tcp # NBD statd (client side)
enbd-sstatd 5052/tcp # NBD statd (server side)
- És egy az inetd.conf-ba is:
enbd-sstatd stream tcp nowait root /usr/sbin/enbd-sstatd enbd-sstatd
Elvben készen vagyunk. Aki okos volt, és átmásolta az indítóscriptet is a munkakönyvtárból (Debian felhasználók e definíció szerint okosak), a /etc/init.d/enbd paranccsal indíthatják enbd szerverüket, örömmel láthatják, hogy kiköp fél oldal üzenetet, majd kényelembe helyezi magát, és vár a kliensek áradatára. Aki nem volt okos, az indíthatja kézzel is a szerverét, a következő parancssor felel meg a fönti konfigsornak:
enbd-server 1234 /home/tudor/melo/raiddoksi/raid1.bin -i elso -b 512
Itt sokat kell vacakolnunk, kernelmodulokkal például, és már a monitorozásra is föl kell készülnünk. Kellenek az enbd-client és enbd-sstatd binárisok.
- Tegyük a helyére az új kernelt és modulokat. Gondoskodjunk arról, hogy a modul betöltődjék induláskor.
- Hozzunk létre device nodeokat. 43-as major számmal kell. Alapértelmezés szerint minden 16. egy major, és 1-16 a minorok, így egy enbd eszköznek 16 partíciója lehet, és 16 enbd eszközünk lehet. Ennek megfelelően a következő shellscript megcsinálja nekünk a nodeokat:
for i in a b c d; do
i_nr=`expr index abcd $i - 1`
mknod /dev/nd$i b 43 $[ $i_nr \* 16 ]
for j in 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15; do
mknod /dev/nd$i$j b 43 $[ $i_nr \* 16 + $j ]
done
done
- Ide is kell /etc/enbd.conf konfigurációs file.
client elso /dev/nda 192.188.242.35 1234 -n 4 -b 512
- A client ... nahát.
- Azonosító, mint fönt.
- Az enbd node, melyre csatlakoztatjuk.
- Az adó ip címe.
- Az adó portja.
- Egyéb opciók. Itt arra kérjük, hogy 4 threadot indítson. 4 threaddal kb. 10%-al gyorsabb lesz, és valamivel nagyobb terhelést okoz a vevőn, mint 2 threaddel. Az igazi különbség a speciális, HA rendszereknél mutatkozhat meg, amikor adatmentésre használjuk az ENBD-t, és mondjuk 3 fizikai összeköttetést használunk.
- Kell két bejegyzés a /etc/services fájlba:
enbd-cstatd 5051/tcp # NBD statd (client side)
enbd-sstatd 5052/tcp # NBD statd (server side)
- És egy az inetd.conf-ba is:
enbd-cstatd stream tcp nowait root /usr/sbin/enbd-cstatd enbd-cstatd
És ennyi. Hódítottam már meg leányt egyszerűbben, de azért nem a legbonyolultabb dolog a világon. Indítani a /etc/init.d/enbd pranccsal lehet. Ha ezt nem akarjuk, akkor a fenti konfigsor parancssori megfelelője:
enbd-client 12.34.56.78 1234 -i elso -b 512 /dev/nda
6.3.4 Diagnosztika, üzemzavarok
Indulás után hihetetlen mennyiségű üzenetet köp ki, méghozzá az indító terminálra, bármit is csinálunk. Természetesen ezeket jegyzi a syslogba is. Az üzenetek tájékoztatnak minket arról, hogy elindította a 4 subthreadot, és hogy használatba vette a megjelölt eszközt. Ha sikerrel járt, és felvették a kapcsolatot, akkor az adó képernyőjén is elkezdenek hömpölyögni az üzenetek.
Az első kapcsolatfelvétel a parancssorban/konfigban megadott porton történik, de a megadott számú subthreadok nyitnk egy új, közös portot, általában az induló port fölött, egyesével. Megadhatjuk, hogy mely portokból válogathat, ez nagyban könnyíti a tűzfalszabályok kijátszását.
A működés közbeni információk forrása (a fecsegős syslog mellett, persze) a
/proc/nbdinfo fájl. Ez sem szűkszavú, hogy úgy mondjam.
# cat /proc/nbdinfo
vurstli:~# cat /proc/nbdinfo
Device a: Open
[a] State: verify, rw, enabled, validated,
last error 0, lives 0, bp 0
[a] Queued: +0R/0W curr (check 0R/0W) +8R/1W max
[a] Buffersize: 262144 (sectors=512, blocks=512)
[a] Blocksize: 512 (log=9)
[a] Size: 5000000KB
[a] Blocks: 0
[a] Sockets: 4 (+) (+) (*) (+)
[a] Requested: 8 (4) (4) (0) (0) 8R/0W
max 1
[a] Despatched: 8 (4) (4) (0) (0) 8R/0W
md5 0W (0 eq, 0 ne, 0 dn)
[a] Errored: 0 (0) (0) (0) (0) 0+0
[a] Pending: 0 (0) (0) (0) (0) 0R/0W+0R/0W
[a] B/s now: 0 (0R+0W)
[a] B/s ave: 0 (0R+0W)
[a] B/s max: 512 (512R+0W)
[a] Spectrum: 11%0 88%1
[a] Kthreads: 0 (0 waiting/0 running/1 max)
[a] Cthreads: 4 (+) (+) (+) (+)
[a] Cpids: 4 (20485) (20486) (20487) (20488)
Mit is próbál közölni velünk? Elsősorban azt, hogy itt a /dev/nda eszközről van szó. Működés közben tanulmányozzuk, sok érdekességet közöl velünk. Öröm látni, ahogy a működést jelző csillagocska vándorol a threadek között, vagy ahogy elosztja a terhelést, s a többi.
Gyakran szokásom a ps axf | grep enbd parancsot is kiadni. Eszközönként 5 sornak kell lennie, és akkor vagyunk bajban, ha ezek közül egy D állapotba kerül. Esetleg több.
20479 ? Ss 0:00 enbd-client [ip] 1234 -i elso -n 4 -b 512 /dev/nda
20485 ? S 0:00 \_ enbd-client [ip] 1234 -i elso -n 4 -b 512 /dev/nda
20486 ? S 0:00 \_ enbd-client [ip] 1234 -i elso -n 4 -b 512 /dev/nda
20487 ? S 0:00 \_ enbd-client [ip] 1234 -i elso -n 4 -b 512 /dev/nda
20488 ? S 0:00 \_ enbd-client [ip] 1234 -i elso -n 4 -b 512 /dev/nda
Ennek a legjellemzőbb oka az, hogy az adónak valami baja esett. Ilyenkor több lehetőségünk is van:
- -e opcióval indítjuk a vevőt. Ez azonnal jelenti a hibákat a ,,felsőbb rétegnek", és így a vevő azt hiszi, hogy meghalt a diszk. Senki sem kerül D állapotba, és az esetet úgy kezelhetjük, mint bármely raid tömbben - hotremove, kijavít, visszailleszt. Civilizált megoldás. De csak raid esetén működik, egy magányos diszknél nem.
- újraindítjuk/rendbe tesszük az adót. Ez alapesetben a legegyszerűbb, de amíg meg nem tesszük, minden résztvevő D állapotban vár. Ha nem sikerül újraindítani, az ismert paraméterekkel indíthatunk egy tartalékadót, de ez nehezen belátható következményekkel járhat. Arra elég lehet, hogy faultyra állítsuk az adott diszket.
- ,,resetelhetjük" az enbd rendszert. Ennek három vállfaja van, a gonosz, a durva, és a kíméletlen.
- kill -SIGUSR1 <pid> paranccsal megkérjük az adott enbd klienst, hogy számoljon el. Lezárja a nyitott kapcsolatokat, a D processzek io-hibával megállnak.
- echo "0" > /proc/nbdinfo, és az egész enbd 5 másodpercre megtorpan, majd elszámol az eddigiekkel. Mintha minden kliensnek küldtünk volna jelet.
- echo "1" > /proc/nbdinfo, és mintha akkor töltöttük volna be a modult. Minden lap tiszta, minden adósság eltűnt.
Sajnos ezen megoldások mindegyike a raid tömb azonnali és fájdalmas halálát okozza. Nem kellene neki, de okozza.
6.4 Élet az ENBD-vel
Ha sikeresen elindítottuk enbd eszközünket, bátran kezeljük úgy, mint bármely blokk-eszközünket, apró fönttartásokkal. Particionáljuk, formázzuk, mountoljuk, írjuk, olvassuk - érezzük magunkat otthon.
Raid5 eszközökön az mke2fs elhasal. Valamilyen módon D állapotba viszi az egész tömböt, mindenestül.
Általában az ext2 sokkal inkább épít a nagy sávszélességre, formázáskor végignyalja az egész diszket. Az XFS ilyet nem csinál. Általában szeretjük az XFS-t.
Hozzunk is létre raidot a /dev/nda és /dev/hda5 eszközökből, és nézzük meg az eredményeket:
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid5]
md3 : active raid1 nda[1] hda5[0]
4883648 blocks [2/2] [UU]
[===========>.........] resync = 56.2% (2747712/4883648)\
finish=6.6min speed=5324K/sec
# mdadm --detail /dev/md3
/dev/md3:
Version : 00.90.01
Creation Time : Wed Oct 13 16:33:14 2004
Raid Level : raid1
Array Size : 4883648 (4.66 GiB 5.00 GB)
Device Size : 4883648 (4.66 GiB 5.00 GB)
Raid Devices : 2
Total Devices : 2
Preferred Minor : 3
Persistence : Superblock is persistent
Update Time : Wed Oct 13 16:33:15 2004
State : clean, resyncing
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Rebuild Status : 61% complete
UUID : 60635427:9fd331df:34c0e2cc:d877dcc3
Events : 0.1
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/hda5
1 43 1 1 active sync /dev/nbd
A legszembetűnőbb, hogy semmi szembetűnő ninsen rajta. A fáradságos munkával megvalósított, kiválóan általánosított blokkeszközök miatt nincsen érdemi különbség a tényleges merevlemezekből és a nem teljesen hagyományos eszközökből ácsolt raid tömbök között. Kezelésük sem különbözik egymástól, és nem is szinkronizál lassabban, mint a buta raid tömbök, amiket eddig láttunk. Formázzuk meg, mountoljuk föl (sync opcióval, hiszen nem teljesítményre, hanem biztonságra utazunk), másoljunk föl rá Létfontosságú Fájlokat, stb.
Érdekes apróság, hogy a /poc/mdstat más néven ismeri az ENBD eszközt, mint az mdadm. Ennek szerintem történelmi okai vannak, régebben nem volt E az NBD előtt, és pár helyen még erre emlékezünk.
Egy igazi raid tömb persze, gyorsabb diszkből áll, és akkor a hálózat szűk keresztmetszet lehet. Nagyon szűk. De ENBD-vel nagyon csekély, pár százalékos overheaddal dolgozunk. Még nem publikált írásomból kiderül, hogy 100 mbites hálón a 10 mbyte/sec, gigabites hálón a 65 mbyte/sec teljesen reális, háztartási körülmények között is elérhető teljesítmény, és ez elegendő. Akinek kevés, ajánlom figyelmébe az ENBD dokumentációját - mondjuk 3 gigabites kártyán át, kártyánként 8 enbd-threaddel kellemesen ki lehetne tömni egy komoly SCSI u320 raid tömböt is. Ez persze felső becslés, arra alapozva, hogy ezt úgysem bírja el semmilyen pc alapú rendszerbusz.
De szálljunk le a fellegekből. Reggel, munkába menet halljuk a híreket: két dolgozó keresztüllőtt, majd csákánnyal felaprított egy Pótolhatatlan Adatokat Tartalmazó Szervert. Sötét balsejtelmeink válnak valóra, mikor érkezésedkor az iroda ajtaján a kényszerzubbonyban vihogó biztonsági őrt kísérik ki. Bizony, pórul járt kedvenc szerverünk. Mit tehetünk ilyenkor? Mivel korábban megvalósítottuk az ENBD-n keresztüli raid tömböt, nem esünk kétségbe:
fifi:~# file /home/tudor/melo/raiddoksi/raid1.bin
/home/tudor/melo/raiddoksi/raid1.bin: Linux rev 1.0
ext3 filesystem data (needs journal recovery)
fifi:~# losetup /dev/loop0 /home/tudor/melo/raiddoksi/raid1.bin
fifi:~# fsck.ext3 /dev/loop0
e2fsck 1.35 (28-Feb-2004)
/dev/loop0: recovering journal
/dev/loop0: clean, 72/611648 files, 27975/1220912 blocks
Mindez az ,,adó" gépen zajlik, ahol van egy szinte tökéletes diszk-másolatunk. A file parancs tulajdonképpen minen fájlról megmondja, mi az, de esetünkben különösen pontos - ext3 filerendszerrel van dolgunk, amely bizony helyreállítást igényel. Föl is illesztjük loopként, rendbe is tesszük (ezt egyébként fölcsatoláskor automatikusan is megteszi a rendszer), és miénk az összes maradék adat. Mountolhatjuk, dolgozhatunk rajta, a fejlesztő kolléga meg nyelje a pasztillákat valahol egy puhafalú szobában.
7 Összefoglalás
Miről is olvashattunk? Megtanultunk pár alapvető raid eljárást, tönkre is tettünk raid tömböket. Aki szeret kísérletezni, az akár a helyreállítást is megpróbálhatta. Megismerkedtünk egy olyan módszerrel is, ami a SAN eszközök képességeit hozza el szabad forrású világunkba. Elég szerényen, de még HA rendszerrel is kísérleteztünk. Mindent összevéve, a ,,nagygépek" világából ismert fogalmak szabad forráskódú, lényegesen olcsóbb, és rendkívül rugalmas megvalósítását láthattuk első kézből.
Félreértés ne essék - aki végigpróbálgatta az itt bemutatott eljárásokat, nem lesz automatikusan hozzáértő. A raid tömbök világa számtalan álnoksággal terhes, sok meglepetéssel járhat, és a tényleges profizmushoz szükséges magabiztosság megszerzéséhez gyakorlat kell, véres és komoly gyakorlat. De ez a kis írás segíthet elindulni az úton, remélem. Ha ezt elértem, akkor már nem hiába szenvedtem ezzel három hétig. Egyébként mostanra eléggé megutáltam ezt a témát, megyek is usert supportálni.
Köszönetnyilvánítás
De előbb fölsorolom azokat, akik segítettek:
- A SZIE Informatikai Hivatala, és annak vezetője, Ritter Dávid, aki ezt a munkát is a többi, munkakörömhöz tartozó feladattal egyenrangúnak ismerte el, és eképpen időt adott hozzá.
- Lajber Zoltán, akivel közösen tartjuk karban a táblázatban is szereplő gépeket, és aki beugrott helyettem tenni-venni, mikor én éppen nagyon nem értem rá.
- Juhász Jácint, aki a még meg nem írt féllábú-raid-install szekcióhoz nyújtott segítséget.
- Korn András, aki építő kritikával járult hozzá a hibák javításához. Konkrétan 3 oldalnyi elvi és gépelési hibával. Egy részét ki is javítottam!
- Pásztor Miklós, aki elhitte rólam, hogy képes vagyok 4 órán át értelmesen beszélni.
- A linux-flame lista közössége, akik szokatlanul pozitív érdeklődéssel fogadták az előadást, és például nem szerveztek bombariadót.
- És végül, de nem utolsó sorban, a szerencsi Linuxtábor közép-haladó nebulóinak, akiken ezt a tananyagot úgy-ahogy kikísérleteztem.
Mi kell még?
Féllábú-raid-install
Irodalomjegyzék
Rendes összefoglaló
File translated from
TEX
by
TTH,
version 3.67.
On 3 Oct 2006, 17:11.